
In today’s data-driven world, organizations are swamped with information from a myriad of sources: user interactions, application logs, social media, IoT devices, and much more. This data arrives in various formats – structured, semi-structured, and unstructured. The challenge isn’t just collecting this data, but storing, processing, and extracting valuable insights from it. Enter the Data Lake.
But what exactly is a data lake, and how does it work? The interactive “Data Lake Architecture Visualisation” demo you’re exploring lets you click through the end-to-end journey of three common file types, JSON, XML, and CSV, as they move from an external source, through an API, into a data lake, and finally into a business-intelligence (BI) dashboard.
This article is your companion guide to that demo. It will:
You can check the demo out here: https://interactivedatalakedemo.foreranger.com/
Beginners’ takeaway: A data lake is like a vast natural reservoir. It collects water (data) from many rivers and streams (sources) in its original, unfiltered form. It stores any data, in any format, until you decide what you want to do with it.
Traditional databases and data warehouses require you to design strict tables and define the structure of your data before loading it (a concept called schema-on-write). A data lake flips that script:
Feature | Data Lake | Data Warehouse |
Schema | On read (decide structure later) | On write (schema enforced upfront) |
Formats | Structured, semi-structured, unstructured | Primarily structured |
Cost per GB | Low (typically object storage) | Higher (database storage) |
Typical uses | Long-term archive, ML model training, log analytics, data exploration | Business reporting, financial statements |
A data lake’s flexibility in storing data in its raw, native format is its superpower. The structure (or schema) is applied only when you need to read and analyse the data (schema-on-read). This is crucial for data scientists who want to explore data in its most detailed form and provides immense flexibility for future, unforeseen analysis.
However, this flexibility can also be its most significant risk: without a plan and proper processes, a tidy lake can devolve into a “data swamp” where data is complex to find or trust. The demo you’re exploring shows how tooling and distinct processing stages help prevent that.
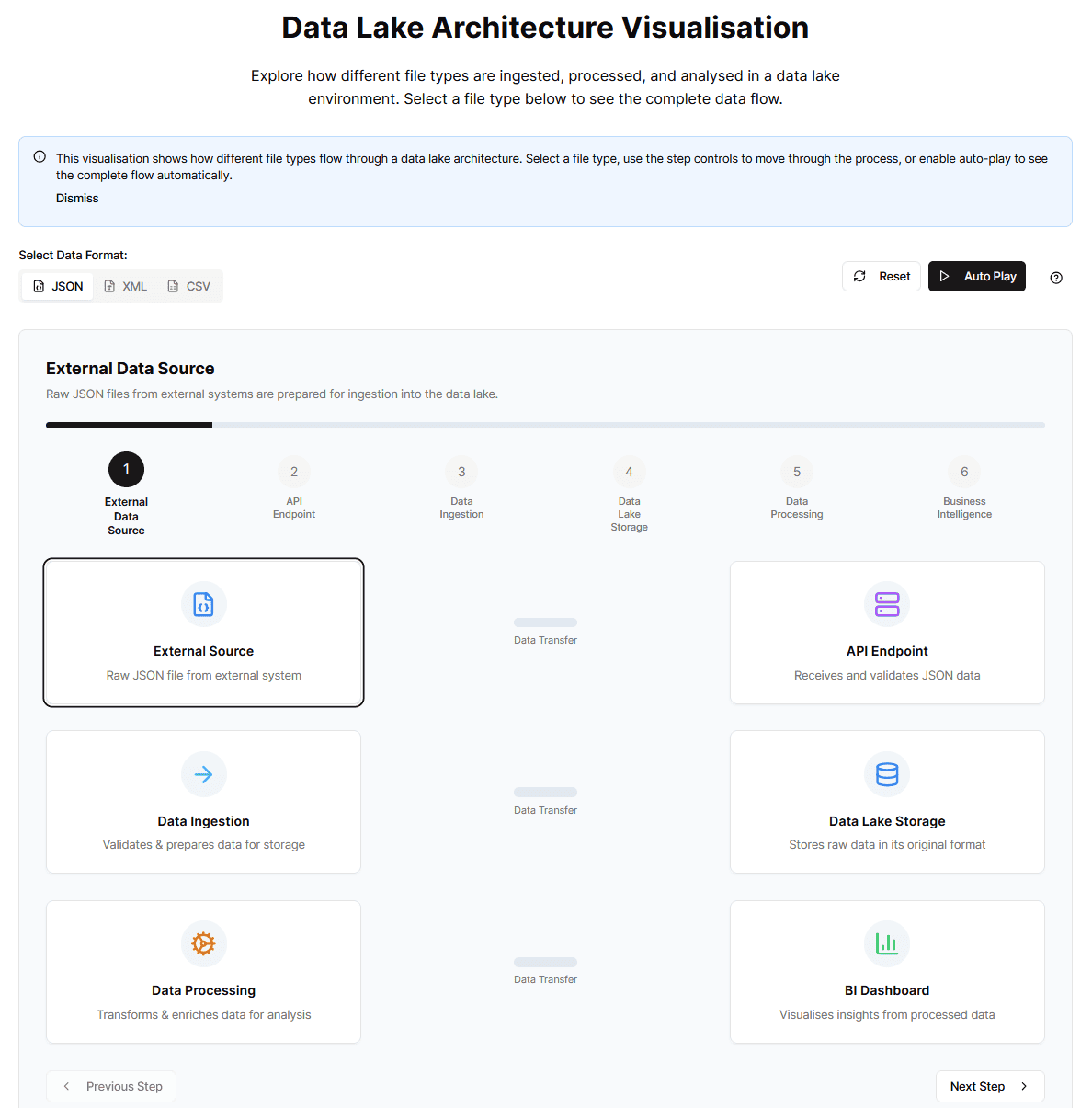
Demo Tie-in: In our demo, notice the “Select Data Format” option at the top-left. You can choose between JSON (often from web apps, APIs), XML (common in enterprise systems), and CSV (tabular data from spreadsheets, databases). This directly illustrates the data lake’s ability to ingest various data types right from the initial “External Data Source” stage.
Keep these terms in mind as you click through the demo:
Our interactive demo breaks down the data lake process into six key stages. As you switch between JSON, XML, and CSV tabs at the top-left:
Let’s explore each stage:
Stage 1: External Data Source
Stage 2: API Endpoint
Stage 3: Data Ingestion
Stage 4: Data Lake Storage
Stage 5: Data Processing
Stage 6: Business Intelligence & Analytics
Tip: Hit the “Autoplay” button in the demo to see all stages animate automatically, or click individual step numbers/indicators to jump non-linearly.
Our demo gives you a visual feel, but why do organisations invest in data lakes?
Our demo provides a foundational understanding. In real-world, sophisticated data lake environments, you’ll encounter more advanced concepts:
This is a popular data organisation pattern within a data lake, structuring data into layers:
Layer | Purpose | Typical File Ownership |
Bronze | Immutable raw data; audit trail | Data engineering |
Silver | Cleaned, conforming, join-ready data | Data engineering |
Gold | Business aggregates, denormalised marts | Analytics / BI teams |
Automated jobs promote data through these layers, often with capabilities like Delta Lake’s time-travel checkpoints so you can roll back to previous versions if needed. Our demo simplifies this but shows the conceptual transition from raw (Bronze-like) to processed (Silver-like) to analysed (Gold-like).
Formats like Delta Lake, Apache Iceberg, and Apache Hudi bring features traditionally found in databases to data lakes built on object storage:
The demo primarily visualises batch data movement (dots flowing then stopping) for clarity. In production, you may switch or combine this with a streaming paradigm for real-time data:
↑ MQTT / Webhook → Kafka Topic → Incremental Lake Table (e.g., using Spark Streaming or Flink) → Real-time Dashboard
As data lakes grow, managing data quality, security, access control, and lineage becomes critical:
Pitfall | Prevention |
Data swamp—no one knows what lives in the bucket | Enforce naming standards, use a data catalog, tag ownership, document data. |
Expensive queries—petabytes scanned for a quick graph | Partition data (e.g., by date/source); use Z-ordering or similar indexing techniques; optimize table formats. |
Duplicate data copies across teams | Promote data through medallion layers instead of duplicating full datasets per team; use views. |
We encourage you to spend time with the Data Lake Architecture Visualisation:
©2025 Foreranger. All rights reserved.